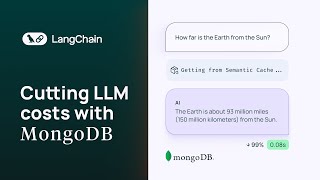
Media Summary: Nitin Kanukolanu, Applied AI Engineer at Redis, focused on This is how to enhance the performance of intelligent applications by implementing Many of your users ask the same question worded differently, and you're paying your
Semantic Caching For Llm Apps Cut Cost Without Wrong Answers Module 3 1 - Detailed Analysis & Overview
Nitin Kanukolanu, Applied AI Engineer at Redis, focused on This is how to enhance the performance of intelligent applications by implementing Many of your users ask the same question worded differently, and you're paying your One common concern of developers building AI applications is how fast Are your AI agents slow, expensive, or repetitive? Large Language Models (LLMs) often waste significant time and money ... Hey there! Welcome to our YouTube deep-dive into
In this tutorial, discover how to save on AI