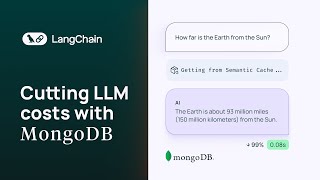
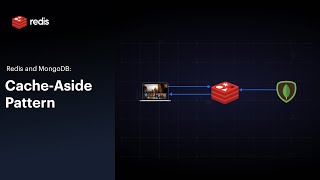
Media Summary: Many of your users ask the same question worded differently, and you're paying your This is how to enhance the performance of intelligent applications by implementing One common concern of developers building AI applications is how fast answers from LLMs will be served to their end users, ...
Cutting Llm Costs With Mongodb Semantic Caching - Detailed Analysis & Overview
Many of your users ask the same question worded differently, and you're paying your This is how to enhance the performance of intelligent applications by implementing One common concern of developers building AI applications is how fast answers from LLMs will be served to their end users, ... Nitin Kanukolanu, Applied AI Engineer at Redis, focused on This video breaks down production-grade RAG system design — including document ingestion, chunking, embeddings, vector search ...