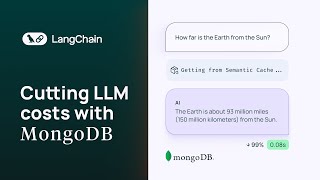
Media Summary: One common concern of developers building AI applications is how fast answers from LLMs will be served to their end users, ... What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ... Your LLM agents are slow and burning cash because they repeat the same expensive calls over and over. In this video, I show ...
A Semantic Cache Using Langchain - Detailed Analysis & Overview
One common concern of developers building AI applications is how fast answers from LLMs will be served to their end users, ... What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ... Your LLM agents are slow and burning cash because they repeat the same expensive calls over and over. In this video, I show ... Are your AI agents slow, expensive, or repetitive? Large Language Models (LLMs) often waste significant time and money ... This is how to enhance the performance of intelligent applications by implementing In this video, we dive into the realm of AI optimization, discussing how to drastically reduce OpenAI API costs and enhance app ...
Nitin Kanukolanu, Applied AI Engineer at Redis, focused on Stop overpaying for your LLM API calls! If you are building AI applications, you've likely noticed that costs scale quickly. Ready to become a certified watsonx Generative AI Engineer? Register now and Tyler Hutcherson, Applied AI Engineering Lead at Redis, explores how There's a new MongoDB YouTube channel dedicated to developers. Click the link to find new tutorials and resources to help you ...