Media Summary: Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Try Voice Writer - speak your thoughts and let AI handle the grammar: Red Hat's Mark Kurtz and Megan Flynn examine
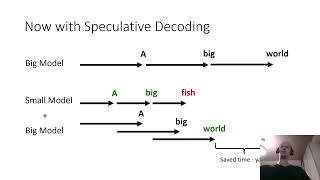
Speculative Speculative Decoding - Detailed Analysis & Overview
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Try Voice Writer - speak your thoughts and let AI handle the grammar: Red Hat's Mark Kurtz and Megan Flynn examine Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... In this episode of PaperX, we dive into " Abstract: We will discuss how vLLM combines continuous batching with
Your LLMs are fast. They could be faster. Richard and Pierce break down arxiv - Become AI Researcher & Train LLM From Scratch ...