Media Summary: Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Try Voice Writer - speak your thoughts and let AI handle the grammar: Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ...
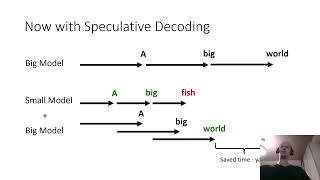
Speculative Decoding In A Nutshell - Detailed Analysis & Overview
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Try Voice Writer - speak your thoughts and let AI handle the grammar: Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... Red Hat's Mark Kurtz and Megan Flynn examine Ever wonder why AI chatbots sometimes feel slow, generating one word at a time? It's because large language models (LLMs) are ... This is a single lecture from a course. If you you like the material and want more context (e.g., the lectures that came before), check ...
In this video, I will show you how to properly configure One Click Templates Repo (free): Advanced Inference Repo (Paid Lifetime ... This video overview explores the mechanics and production performance of Your local LLM generates one word at a time. Painfully slowly. What if you could get 2-3x faster with the same model, same output, ...










![Why using a dumb language model can speed up a smarter one: Speculative Decoding [Lecture]](https://i.ytimg.com/vi/VnvhD8_E7AQ/mqdefault.jpg)