Media Summary: In this video, we dive into a very interesting topic " ERRATA: - In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should ... Try Voice Writer - speak your thoughts and let AI handle the grammar: In this video, I explain RoPE - Rotary ...
Self Attention With Relative Position Representations Summary - Detailed Analysis & Overview
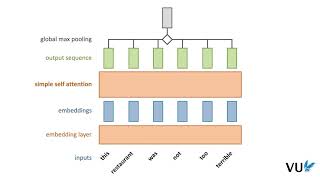
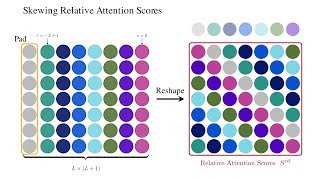
In this video, we dive into a very interesting topic " ERRATA: - In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should ... Try Voice Writer - speak your thoughts and let AI handle the grammar: In this video, I explain RoPE - Rotary ... Davidson CSC 381: Deep Learning, Fall 2022. To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ... In this quick and visual walkthrough, we break down the core idea behind modern AI models like Transformers, BERT, and GPT.






![How Rotary Position Embedding Supercharges Modern LLMs [RoPE]](https://i.ytimg.com/vi/SMBkImDWOyQ/mqdefault.jpg)