Media Summary: ERRATA: - In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should ... Davidson CSC 381: Deep Learning, Fall 2022. ... address some fundamental limitations of
Lecture 12 1 Self Attention - Detailed Analysis & Overview
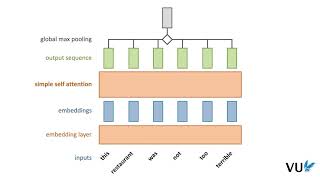
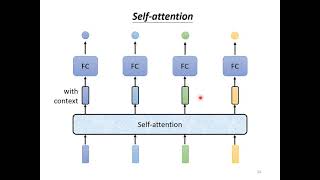
ERRATA: - In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should ... Davidson CSC 381: Deep Learning, Fall 2022. ... address some fundamental limitations of All right let's go through each of the things we need to take care of in order to turn this basic Self Attention works by computing attention scores for each word in a sequence based on its relationship with every other word ... In this third video of our Transformer series, we're diving deep into the concept of Linear Transformations in
In this video, we briefly introduce transformers and provide an introduction to the intuition behind For more information about Stanford's online Artificial Intelligence programs visit: This Let's understand the intuition, math and code of Intro to Modern AI online course. For more information and to enroll, please visit

















![[ML 2021 (English version)] Lecture 12: Transformer (1/2)](https://i.ytimg.com/vi/zmOuJkH9l9M/mqdefault.jpg)
