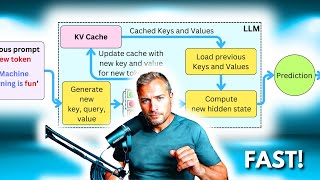
Media Summary: In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Try Voice Writer - speak your thoughts and let AI handle the grammar: The Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ...
Kv Cache The Trick That Makes Llms Faster - Detailed Analysis & Overview
In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Try Voice Writer - speak your thoughts and let AI handle the grammar: The Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... Same prompt. Same model. The first call costs $1.00. The second costs $0.05. Same words — 20× cheaper. The reason isn't a ... This is a single lecture from a course. If you you like the material and want more context (e.g., the lectures that came before), check ... Ever wondered how large language models like GPT respond so
Ever wonder how even the largest frontier The attention mechanism is known to be pretty slow! If you are not careful, the time complexity of the vanilla attention can be ... Try out and get your free credits now on GenSpark AI, as well as unlimited use of AI Chat and AI Image in 2026 for paid users ... Ever notice how AI replies feel slow… and then suddenly Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Have you ever wondered how massive language models like DeepSeek-R1 and Qwen3 handle complex math problems without ...






![KV Caching: Speeding up LLM Inference [Lecture]](https://i.ytimg.com/vi/_quDGLpNols/mqdefault.jpg)