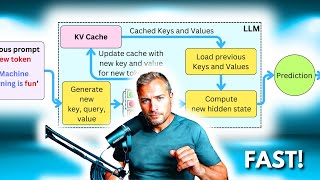
Media Summary: The attention mechanism is known to be pretty slow! If you are not careful, the In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ...
How To Reduce Llm Decoding Time With Kv Caching - Detailed Analysis & Overview
The attention mechanism is known to be pretty slow! If you are not careful, the In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... Try Voice Writer - speak your thoughts and let AI handle the grammar: The Open-source LLMs are great for conversational applications, but they can be difficult to scale in production and deliver latency ... This is a single lecture from a course. If you you like the material and want more context (e.g., the lectures that came before), check ...
Same prompt. Same model. The first call costs $1.00. The second costs $0.05. Same words — 20× cheaper. The reason isn't a ... Ever wondered how large language models like GPT respond so fast without recomputing everything from scratch? In this video, I ... Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Go to for P99 CONF talks on demand and to learn more. . . . . . Most devs are using LLMs daily but don't have a clue about some of the fundamentals. Understanding tokens is crucial because ...
Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ...





![KV Caching: Speeding up LLM Inference [Lecture]](https://i.ytimg.com/vi/_quDGLpNols/mqdefault.jpg)













