Media Summary: In this AI Research Roundup episode, Alex discusses the paper: ' In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the The Shannon-Prime framework introduces an algebraic approach to transformer computation by representing model operations ...
Dualpath Breaking Kv Cache Bottlenecks In Llms - Detailed Analysis & Overview
In this AI Research Roundup episode, Alex discusses the paper: ' In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the The Shannon-Prime framework introduces an algebraic approach to transformer computation by representing model operations ... Try Voice Writer - speak your thoughts and let AI handle the grammar: The In this AI Research Roundup episode, Alex discusses the paper: 'OCTOPUS: Optimized Ever wonder how even the largest frontier
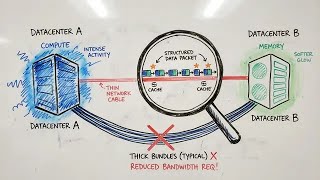
Go to for P99 CONF talks on demand and to learn more. . . . . . Have you ever wondered how massive language models like DeepSeek-R1 and Qwen3 handle complex math Paper: Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter (2604.15039) Published: 16 Apr ... In this AI Research Roundup episode, Alex discusses the paper: 'Self-Pruned Key-Value Attention: Learning When to Write by ... In this AI Research Roundup episode, Alex discusses the paper: 'Language Models Need Sleep' Transformer-based large ...