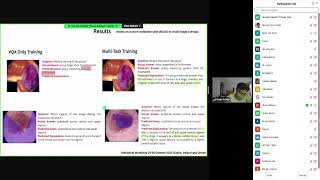
Media Summary: Mikyas Desta, Larry Chen, Tomasz Kornuta Visual Question Answering is a novel problem domain where multi-modal inputs must ... Original paper: Title: Intelligence Analysis of Language Models Authors: Liane Galanti, Ethan ... Handong Zhao, Quanfu Fan, Dan Gutfreund, Yun Fu We present a novel approach to enhance the challenging task of Visual ...
Wacv18 Object Based Reasoning In Vqa - Detailed Analysis & Overview
Mikyas Desta, Larry Chen, Tomasz Kornuta Visual Question Answering is a novel problem domain where multi-modal inputs must ... Original paper: Title: Intelligence Analysis of Language Models Authors: Liane Galanti, Ethan ... Handong Zhao, Quanfu Fan, Dan Gutfreund, Yun Fu We present a novel approach to enhance the challenging task of Visual ... Amrita Saha, Megha Nawhal, Mitesh M. Khapra, Vikas Raykar In many visual domains (like fashion, furniture etc.) the search for ... If you have any copyright issues on video, please send us an email at khawar512.com Top CV and PR Conferences: ... ICCV17 1138 Inferring and Executing Programs for Visual
Sanjay Subramanian joined the Cohere For AI Open Science Community's Geo Regional Asia group to present Visual Learn all the ways Microsoft is a part of CVPR 2020: Paper presentation at ECCV 2020. Summary: We design ROLL, a model for knowledge- REXUP: I REason, I EXtract, I UPdate with Structured Compositional IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) 2026 In this paper, we propose QuatRoPE, a novel 3D ... Multi-Task Learning for Visually Grounded
Invited Talk by Jiasen Lu on "Multi-Task Vision and Language Representation Learning" at the Visual Question Answering and ...










![[ECCV 2020] Knowledge-Based VideoQA with Unsupervised Scene Descriptions](https://i.ytimg.com/vi/KCUUvSpf-Qo/mqdefault.jpg)

![[CVPR’26] Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models](https://i.ytimg.com/vi/ujhBsJKk-UQ/mqdefault.jpg)