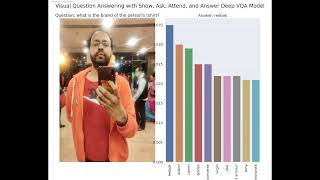
Media Summary: Handong Zhao, Quanfu Fan, Dan Gutfreund, Yun Fu We present a novel approach to enhance the challenging task of Authors: Pan Lu (Tsinghua University); Lei Ji (Microsoft); Wei Zhang (East China Normal University); Nan Duan (Microsoft); Ming ... This small demo shows a Pal Robotics TIAGo++ robot executing a basic
Visual Question Answering Gui - Detailed Analysis & Overview
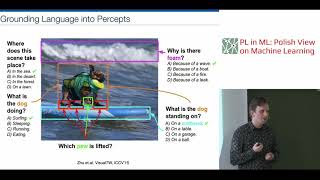
Handong Zhao, Quanfu Fan, Dan Gutfreund, Yun Fu We present a novel approach to enhance the challenging task of Authors: Pan Lu (Tsinghua University); Lei Ji (Microsoft); Wei Zhang (East China Normal University); Nan Duan (Microsoft); Ming ... This small demo shows a Pal Robotics TIAGo++ robot executing a basic ... Vision Language Models (VLMs), which combine text and image processing for tasks like Invited Lecture at the PL in ML: Polish View on Machine Learning 2018 Conference (plinml.mimuw.edu.pl). Abstract: Owing to ... Copyright: PolyU, XMLGroup Creator: Bo LIU.
This tutorial gives you a glimpse into the Source code and models at This thesis studies methods to solve This is the spotlight video for the ICCV 2015 paper "VQA: Damien Teney; Lingqiao Liu; Anton van den Hengel This paper proposes to improve Bottom-Up and Top-Down Attention for Image Captioning and The work was done as a part of Vision and Language course at Georgia Institute of Technology. The work proposes a hybrid ...
Advances in deep learning keep producing impressive results at the junction of computer vision and natural language processing. This video is about Ask Me Anything: Free-Form ai The problem of answering questions about an image is popularly known as Presentation and Code walkthrough for the deep learning based VQA application.