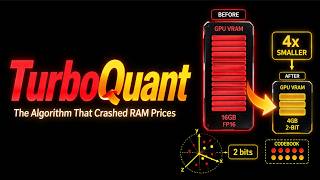
Media Summary: Disclaimer: This video is generated with Google's NotebookLM. Stop overpaying for VRAM. Google just released Long-context AI gets expensive fast, and one of the biggest reasons is KV cache memory. In this video, I explain
Turboquant Randomness - Detailed Analysis & Overview
Disclaimer: This video is generated with Google's NotebookLM. Stop overpaying for VRAM. Google just released Long-context AI gets expensive fast, and one of the biggest reasons is KV cache memory. In this video, I explain Every time you feed an AI a long document or a massive codebase, it chokes, slows down, and eats through your GPU memory . Link to our newsletter: Google just dropped something that could completely change how AI systems run ... In this video, we break down the core ideas behind the
Details the development and implementation of

![[updated] The Algorithmic Shockwave by Google TurboQuant](https://i.ytimg.com/vi/BIXD7lhfcBE/mqdefault.jpg)
![[Podcast] TurboQuant & Randomness](https://i.ytimg.com/vi/Z6roM90d1NM/mqdefault.jpg)