Media Summary: Is your AI too slow or using too much memory? Welcome to ITTECHTARUN channel blog : Subscribe to my channel to get more videos. Are you running out of VRAM when running Large Language Models? Meet
Trending Paper Turboquant Explained Near Optimal Online Vector Quantization Ml - Detailed Analysis & Overview
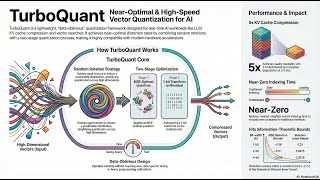
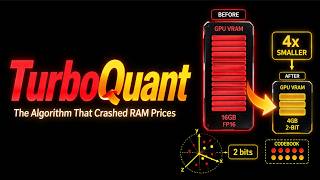
Is your AI too slow or using too much memory? Welcome to ITTECHTARUN channel blog : Subscribe to my channel to get more videos. Are you running out of VRAM when running Large Language Models? Meet LLMs can burn through 30 GB of memory just to hold a single long conversation — AI models are getting bigger every year, and memory is quickly becoming the biggest bottleneck. Larger models need more ... Join my free group: NY Summit in Aug 3rd: Twitter: ...
This video is complete breakdown of a new research from google Run massive AI models on your laptop! Learn the secrets of LLM
![[Trending paper] TurboQuant Explained: Near-Optimal Online Vector Quantization #ml](https://i.ytimg.com/vi/UuZ_dhXb3w0/mqdefault.jpg)











![Next Wave of AI: Client-Side Edge AI PCs Begin NOW! [LIVE]](https://i.ytimg.com/vi/TqYswfdOBEA/mqdefault.jpg)




