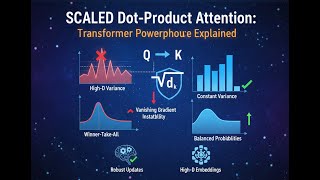
Media Summary: Scaling Self Attention in Scaled Dot Product Attention is crucial for stabilizing training, optimizing dataset utilization ... This video provides a detailed, conceptual, and mathematical justification for the Ever wondered how AI models like GPT and BERT understand context so well? The answer lies in
Scaled Dot Product Attention Explained - Detailed Analysis & Overview
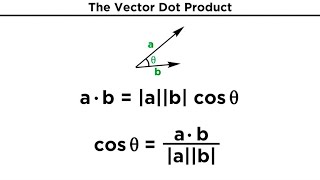
Scaling Self Attention in Scaled Dot Product Attention is crucial for stabilizing training, optimizing dataset utilization ... This video provides a detailed, conceptual, and mathematical justification for the Ever wondered how AI models like GPT and BERT understand context so well? The answer lies in Why do we divide by the square root of the key dimensions in Click Clipped from the super long shaders for beginners stream of two days ago! Note that this is for two normalized vectors, it's a ... We learned how to add and subtract vectors, and we learned how to multiply vectors by scalars, but how can we multiply two ...
Imagine you are in a classroom. The teacher asks a question. Each student (token) pays To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ... Check out the latest (and most visual) video on this topic! The Celestial Mechanics of Breaking down how Large Language Models work, visualizing how data flows through. Instead of sponsored ad reads, these ...