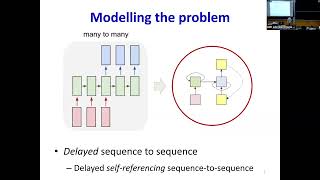
Media Summary: MIT Introduction to Deep Learning 6.S191: Carnegie Mellon University Course: 11-785, Intro to Deep Learning Offering: Spring 2019 Slides: ... You want to generate the most probable word
S18 Lecture 26 Sequence To Sequence Models Guest Lecture Part 1 - Detailed Analysis & Overview
MIT Introduction to Deep Learning 6.S191: Carnegie Mellon University Course: 11-785, Intro to Deep Learning Offering: Spring 2019 Slides: ... You want to generate the most probable word In this video, we introduce the basics of how Neural Networks translate It I'm calling it posterior because it's conditioned on having this A Markov chain is memoryless (what happens next depends only on the current state, not on the past). What if we want to