Media Summary: Summary of my research paper written for partial fulfillment of an honours degree from The University of the Witwatersrand in ... Hands-on whiteboard session on every step of the PPO algorithm! *Support me by buying a copy of the whiteboard:* ... Let's talk about a Reinforcement Learning Algorithm that ChatGPT
Reward Structures For Robotic Locomotion Tasks Using Proximal Policy Optimization - Detailed Analysis & Overview
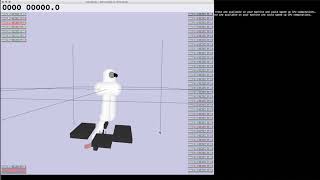
Summary of my research paper written for partial fulfillment of an honours degree from The University of the Witwatersrand in ... Hands-on whiteboard session on every step of the PPO algorithm! *Support me by buying a copy of the whiteboard:* ... Let's talk about a Reinforcement Learning Algorithm that ChatGPT Reward-Adaptive Reinforcement Learning: Dynamic Policy Gradient Optimization for Bipedal Locomotion Reinforcement Learning: Try to get the Human Proximal Policy Optimization - Custom Reacher task 1
Proximal Policy Optimization: Peg Insertion Task Thank you thank you possible so today I'm going to present the possible