Media Summary: Author: Bernardo Avila Pires, Csaba Szepesvari. Here we introduce dynamic programming, which is a cornerstone of What is the difference between model-free and
Policy Error Bounds For Model Based Reinforcement Learning With Factored Linear Models - Detailed Analysis & Overview
Author: Bernardo Avila Pires, Csaba Szepesvari. Here we introduce dynamic programming, which is a cornerstone of What is the difference between model-free and Yes very good points yes oh so you're hitting exactly on the main Presentation for our paper 'Adaptive Discretization for Markov Decision Processes or MDPs explained in 5 minutes Series: 5 Minutes with Cyrill Cyrill Stachniss, 2023 Credits: Video by ...
Summary of our IROS 2025 Publication: www.arxiv.org/abs/2503.02552. Lecture 6 of a 6-lecture series on the Foundations of Deep RL Topic: For more information about Stanford's Artificial Intelligence programs visit: To follow along with the course, ... Panel discussion on the relation of theory and practice in ... go back and forth between evaluating the This video introduces the variety of methods for
For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: Andrew ...






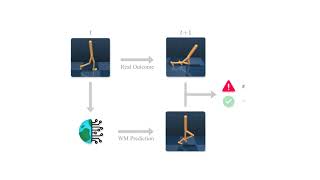




![[Paper Summary] Objective Mismatch in Model-based Reinforcement Learning](https://i.ytimg.com/vi/OcVGm7b_bug/mqdefault.jpg)






