Media Summary: Inside my school and program, I teach you my system to become an AI engineer or freelancer. Life-time access, personal help by ... In this step-by-step tutorial, I'll show you how to deploy and serve Speaker: Maksim Khadkevich, Sr. Software Engineering Manager, Dynamo,
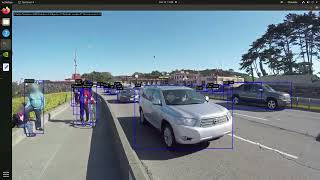
Nvidia Deepstream Multiple Model Inferencing Demo - Detailed Analysis & Overview
Inside my school and program, I teach you my system to become an AI engineer or freelancer. Life-time access, personal help by ... In this step-by-step tutorial, I'll show you how to deploy and serve Speaker: Maksim Khadkevich, Sr. Software Engineering Manager, Dynamo, Timestamps: 00:00 - Intro 01:24 - Technical In this episode, we'll explore various ways DGX Spark can help engineering teams building Generative AI applications by iterating ... AI factories are the new industrial engines — and their profitability hinges on how efficiently they generate intelligence. The rise of ...