Media Summary: Learn how to implement distributed and scalable deep learning (DL) Adam Grzywaczewski and Adolf Hohl hold are two session Mode Parallel, Gradient Accumulation, Data Parallel
Nvaitc Webinar Multi Gpu Training Using Horovod - Detailed Analysis & Overview
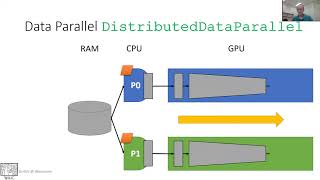
Learn how to implement distributed and scalable deep learning (DL) Adam Grzywaczewski and Adolf Hohl hold are two session Mode Parallel, Gradient Accumulation, Data Parallel Learn how to do Distributed Data Parallelism Distributed Gradient Descent with Horovod During a March 2019 meetup hosted at Uber's SF office, Uber senior software engineer Alex Sergeev discusses how frameworks ...
In the third video of this series, Suraj Subramanian walks This video is an in-depth presentation of the The Piz Daint supercomputer at CSCS provides an ideal platform for supporting intensive deep learning workloads as it ... ai.bythebay.io Nov 2025, Oakland, full-stack AI conference Scale By the Bay 2019 is held on November 13-15 in sunny Oakland, ...









![[Uber Open Source ] Distributed Deep Learning with Horovod -- Alex Sergeev](https://i.ytimg.com/vi/D1By2hy4Ecw/mqdefault.jpg)





