Media Summary: Chenliang Xu (University of Rochester) In this talk, I will discuss how to Hi everyone i'm di hu in this tutorial i will give an introduction about salesforce Presentation O-2B-02 of European Conference on Computer
Multi Level Alignment In Audio Visual Scene Generation And Learning - Detailed Analysis & Overview
Chenliang Xu (University of Rochester) In this talk, I will discuss how to Hi everyone i'm di hu in this tutorial i will give an introduction about salesforce Presentation O-2B-02 of European Conference on Computer TL;DR: New benchmark EntityBench reveals AI video models lose entity consistency sharply after just 48 shots—and proposes ... We present a self-supervised approach for We introduce SceneBench, a new benchmark for evaluating how well
This sample video, based on a fictitious meeting room, shows that one minute is enough time to show someone the basics of their ... Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation Full paper: Presenter: Nandita Bhaskar Stanford University, USA Abstract: Pre-trained ... RWTH Artificial Intelligence Colloquium series, talk 1 Speaker: Prof. Bastian Leibe (RWTH Aachen University) Title: ... brains can determine the location of a Dr. Ruohan Gao, Postdoctoral Fellow at Stanford University, presented a talk in the MERL Seminar Series on September 28, 2021 ...
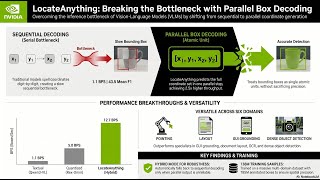
MERL Intern Moitreya Chatterjee presents the paper titled " Can AI find objects in an image instantly? LocateAnything is a game-changer that lets AI "see" and "box" items all at once, ...













![[MERL Seminar Series 2021] Look and Listen: From Semantic to Spatial Audio-Visual Perception](https://i.ytimg.com/vi/ZKXqi4b9mls/mqdefault.jpg)
![[ICCV 2021] Visual Scene Graphs for Audio Source Separation](https://i.ytimg.com/vi/wn9T_GBQbyE/mqdefault.jpg)