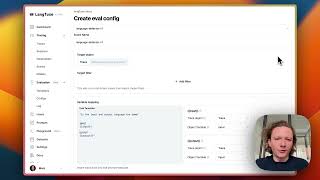
Media Summary: Many users have millions of traces and observations. We've made it easier to filter and We're introducing a set of upgrades to make complex agents radically easier to understand and debug: - Agent Tools now surface ... The Evaluator Library lets you use LLM-as-a-Judge evals to monitor and score key metrics for your LLM applications or AI agents.
Langfuse Launch Week 3 Day 1 Full Text Search - Detailed Analysis & Overview
Many users have millions of traces and observations. We've made it easier to filter and We're introducing a set of upgrades to make complex agents radically easier to understand and debug: - Agent Tools now surface ... The Evaluator Library lets you use LLM-as-a-Judge evals to monitor and score key metrics for your LLM applications or AI agents. Custom Dashboards save views that show the numbers you care about and keep every team on top of what ... Comments now support and emoji reactions, making it easier to collaborate with your team directly in Want to start freelancing? Let me help: Want to learn real AI Engineering? Go here: ...
Hi my name is Max co-founder of l fuse and today I want to In this video our Co-Founder & CEO Marc walks you through the Evaluations product of the Introducing LLM-as-a-judge Evaluation for Dataset Experiments in This video explains how to use OpenTelemetry and Turn production failures into repeatable evals by capturing failing LLM runs with