Media Summary: 발표자: 석사과정 4학기 한주희 - 본 영상은 facebook ai에 2021년 발표한 “ [1] Presenter: Yoonseung Lee [2] Paper: - Training data-efficient image transformers & distillation through attention (https ... Papers / Resources ▭▭▭ Colab Notebook: ...
Ds Interface Training Data Efficient Image Transformers Distillation Through Attention - Detailed Analysis & Overview
발표자: 석사과정 4학기 한주희 - 본 영상은 facebook ai에 2021년 발표한 “ [1] Presenter: Yoonseung Lee [2] Paper: - Training data-efficient image transformers & distillation through attention (https ... Papers / Resources ▭▭▭ Colab Notebook: ... This ten hour compilation brings together everything that I have taught about Vision 重传, PPT: 这篇是真没看懂, 怎么突然就加入蒸馏了~~~




![[DS Interface] Training data-efficient image transformers & distillation through attention](https://i.ytimg.com/vi/i-w-D_TI7LE/mqdefault.jpg)
![[Paper Review] Training data-efficient image transformers & distillation through attention](https://i.ytimg.com/vi/oHnv_S9N1J8/mqdefault.jpg)



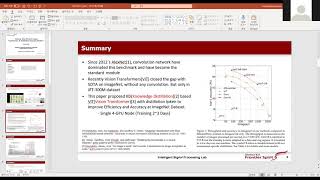




![[ECCV2024]The Role of Masking for Efficient Supervised Knowledge Distillation of Vision Transformers](https://i.ytimg.com/vi/bNpXOobWkmU/mqdefault.jpg)




