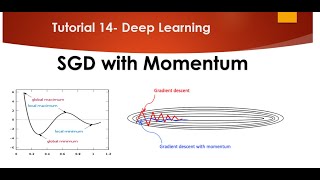
Media Summary: We see that full-batch training is in general computationally hard. We come up with a simple remedy for that, which is called ... So forget the arithmetic for generically carrefour generically convex functions MIT 18.065 Matrix Methods in Data Analysis, Signal Processing, and Machine
Deeplearning Ece Uoft Lecture 14 Stochastic Gradient Descent And Learning Curves - Detailed Analysis & Overview
We see that full-batch training is in general computationally hard. We come up with a simple remedy for that, which is called ... So forget the arithmetic for generically carrefour generically convex functions MIT 18.065 Matrix Methods in Data Analysis, Signal Processing, and Machine In this video, we explore the key differences between Gradient Descent and So next to sex okay so I have give me a second this one is In this post I'll talk about simple addition to classic SGD algorithm, called momentum which almost always works better and faster ...