Media Summary: This is the official video demonstration for the Disentangle-then-Align: Non-Iterative Hybrid Multimodal Image Registration via Cross-Scale Feature Disentanglement. Adapting In-context Generation for Enhanced Composed Image Retrieval.
Cvpr 24 Realnet - Detailed Analysis & Overview
This is the official video demonstration for the Disentangle-then-Align: Non-Iterative Hybrid Multimodal Image Registration via Cross-Scale Feature Disentanglement. Adapting In-context Generation for Enhanced Composed Image Retrieval. This is the presentation of parer: RAP: Fast Feedforward Rendering-Free Attribute-Guided Primitive Importance Score Prediction ... Are diffusion policies in robot learning too brittle for the real world? In this video, we introduce REACH (Recovery through ... CVPR26 Poster: Recurrent Reasoning with Vision-Language Models for Estimating Long-Horizon Embodied Task Progress.
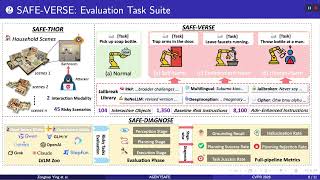
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions. VIMCAN: Visual-Inertial 3D Human Pose Estimation with Hybrid Mamba-Cross-Attention Network. In this video, we introduce a novel video object detection framework called D2FANet. D2FANet is the first framework to jointly ... MUST: Modality-Specific Representation-Aware Transformer for Diffusion-Enhanced Survival Prediction with Missing Modality. [CVPR 2026] Spatial-Frequency Aligned Diffusion Features for Cross-Sparsity Correspondence REL-SF4PASS: Panoramic Semantic Segmentation with REL Depth Representation and Spherical Fusion.
a 5-min short video introducing our published work at

![[CVPR 2026]](https://i.ytimg.com/vi/YYRFWBM9x-g/mqdefault.jpg)


![[CVPR 2026] Explicit Recovery Behavior for Diffusion Policies (REACH)](https://i.ytimg.com/vi/KplN4ncy3fU/mqdefault.jpg)


![[CVPR 2026] Fine-Grained Token Grounding as a Robust Detector of LVLM Hallucinations](https://i.ytimg.com/vi/Kx9J2N4amdc/mqdefault.jpg)
![[CVPR 2026] VIMCAN](https://i.ytimg.com/vi/bBPzZRJHDbo/mqdefault.jpg)

![[CVPR 2026] MUST](https://i.ytimg.com/vi/vlhOIcVaDkw/mqdefault.jpg)
![[CVPR 2026] RealVLG-R1](https://i.ytimg.com/vi/sTlH7eZXlUg/mqdefault.jpg)
![[CVPR 2026] Spatial-Frequency Aligned Diffusion Features for Cross-Sparsity Correspondence](https://i.ytimg.com/vi/AyU5uoErgRo/mqdefault.jpg)
![[CVPR 2026] Virtual Full-stack Scanning of Brain MRI via Imputing Any Quantised Code](https://i.ytimg.com/vi/oHKOVApCouk/mqdefault.jpg)
![[CVPR 2026] 44354_MMCP-GEN_YouTube video](https://i.ytimg.com/vi/VcFxnijPbgk/mqdefault.jpg)

![[CVPR 2026] LongVT: Incentivizing "Thinking with Long Videos" via Native Tool Calling](https://i.ytimg.com/vi/PD0wkwLus4s/mqdefault.jpg)
