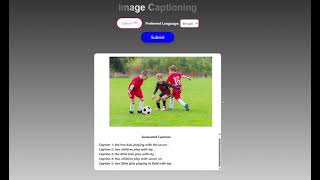
Media Summary: CVPR 2020 - Meshed-Memory Transformer for Image Captioning We propose an end-to-end model which generates Advances in representation learning have led to great success in understanding and generating data in various domains.
Cvpr 2020 Meshed Memory Transformer For Image Captioning - Detailed Analysis & Overview
CVPR 2020 - Meshed-Memory Transformer for Image Captioning We propose an end-to-end model which generates Advances in representation learning have led to great success in understanding and generating data in various domains. Authors: Longteng Guo, Jing Liu, Xinxin Zhu, Peng Yao, Shichen Lu, Hanqing Lu Description: Self-attention (SA) network has ... Learn all the ways Microsoft is a part of Authors: Jia Chen, Qin Jin Description: Sequence-level learning objective has been widely used in
In this video, we review the SHViT (Single-Head Vision Authors: Yingwei Pan, Ting Yao, Yehao Li, Tao Mei Description: Recent progress on fine-grained visual recognition and visual ... Steven J. Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, Vaibhava Goel Recently it has been shown that ... Computer Vision Lab (CVL) made substantial contributions to the IEEE/CVF Conference on Computer Vision and Pattern ... Straight to the Point: Fast-forwarding Videos via Reinforcement Learning Using Textual Data, The model uses a combination of VGG16 for feature extraction and


![[CVPR 2020 Tutorial] Talk #3 Visual Captioning by Luowei Zhou](https://i.ytimg.com/vi/Zn5uFGsq4j4/mqdefault.jpg)