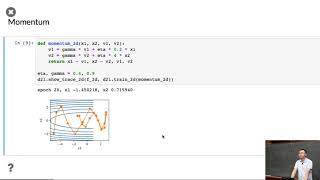
Media Summary: Take the Deep Learning Specialization: Check out all our courses: Subscribe to ... Dive into Deep Learning UC Berkeley, STAT 157 Slides are at The book is at Have you ever wondered why your neural network training gets stuck or converges painfully slowly? Traditional optimizers use a ...
2 4 How Does Adagrad Works - Detailed Analysis & Overview
Take the Deep Learning Specialization: Check out all our courses: Subscribe to ... Dive into Deep Learning UC Berkeley, STAT 157 Slides are at The book is at Have you ever wondered why your neural network training gets stuck or converges painfully slowly? Traditional optimizers use a ... Connect with us on Social Media! Instagram: Threads: ... 263 Adaptive Learning Rate Schedules AdaGrad and RMSprop(GRADIENT DESCENT & LEARNING RATE SCHEDULES) Adam Optimizer Explained in Detail. Adam Optimizer is a technique that reduces the time taken to train a model in Deep Learning.
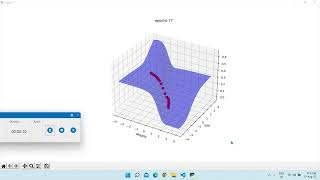
In deep learning, choosing the right learning rate is crucial. If it's too high, we might overshoot the optimal solution. If it's too low, ... Visual and intuitive Overview of stochastic gradient descent in 3 minutes. ------------------- References: - The third explanation is ... to get started with AI engineering, check out this Scrimba course: ...