Media Summary: Authors: Zehua Zhang (Indiana University)*; David Crandall (Indiana University) Description: We present a novel technique for ... We explore spatial context as a source of free and plentiful supervisory signal for training a rich visual Project page: 3-minute overview for "Self-supervised Co-Training for
1204 Unsupervised Video Representation Learning By Bidirectional Feature Prediction - Detailed Analysis & Overview
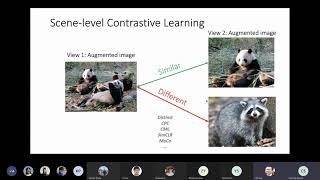
Authors: Zehua Zhang (Indiana University)*; David Crandall (Indiana University) Description: We present a novel technique for ... We explore spatial context as a source of free and plentiful supervisory signal for training a rich visual Project page: 3-minute overview for "Self-supervised Co-Training for Authors: AJ Piergiovanni, Anelia Angelova, Michael S. Ryoo Description: We present a new method to learn Oral Presentation for the paper "Self-Supervised Contrastive [CS576] Momentum Contrast for Unsupervised Visual Representation Learning
Linus Ericsson, Henry Gouk, Chen Change Loy, and Timothy M. Hospedales. "Self-Supervised





![[NeurIPS'20] Self-supervised Co-Training for Video Representation Learning](https://i.ytimg.com/vi/oMcd6maQgQk/mqdefault.jpg)






![[CS576] Momentum Contrast for Unsupervised Visual Representation Learning](https://i.ytimg.com/vi/vKOVSArWj28/mqdefault.jpg)